Develop a FEDn project
This guide explains how a FEDn project is structured, and details how to develop your own project. We assume knowledge of how to run a federated learning project with FEDn, corresponding to the tutorial: Getting started with FEDn.
Overview
A FEDn project is a convention for packaging/wrapping machine learning code to be used for federated learning with FEDn. At the core, a project is a directory of files (often a Git repository), containing your machine learning code, FEDn entry points, and a specification of the runtime environment for the client (python environment or a Docker image). The FEDn API and command-line tools provide functionality to help a user automate deployment and management of a project that follows the conventions.
The structure of a FEDn project
We recommend that projects have the following folder and file structure, here illustrated by the ‘mnist-pytorch’ example from the Getting Started Guide:
The content of the client folder is what we commonly refer to as the compute package. It contains modules and files specifying the logic of a single client.
The file fedn.yaml is the FEDn Project File. It is used by FEDn to get information about the specific commands to run when building the initial ‘seed model’,
and when a client recieves a training request or a validation request from the server.
These commmands are referred to as the entry points.
The compute package (client folder)
The Project File (fedn.yaml)
FEDn uses a project file ‘fedn.yaml’ to specify which entry points to execute when the client recieves a training or validation request, and (optionally) what runtime environment to execute those entry points in. There are up to four entry points:
build - used for any kind of setup that needs to be done before the client starts up, such as initializing the global seed model.
startup - invoked immediately after the client starts up and the environment has been initalized.
train - invoked by the FEDn client to perform a model update.
validate - invoked by the FEDn client to perform a model validation.
To illustrate this, we look the fedn.yaml from the ‘mnist-pytorch’ project used in the Getting Started Guide:
python_env: python_env.yaml
entry_points:
build:
command: python model.py
startup:
command: python data.py
train:
command: python train.py
validate:
command: python validate.py
In this example, all entrypoints are python scripts (model.py, data.py, train.py and validate.py). They are executed by FEDn using the system default python interpreter ‘python’, in an environment with dependencies specified by “python_env.yaml”. Next, we look at the environment specification and each entry point in more detail.
Environment (python_env.yaml)
FEDn assumes that all entry points (build, startup, train, validate) are executable within the client’s runtime environment. You have two main options to handle the environment:
Let FEDn create and initalize the environment automatically by specifying
python_env. FEDn will then create an isolated virtual environment and install the dependencies specified inpython_env.yamlinto it before starting up the client. FEDn currently supports Virtualenv environments, with packages on PyPI.Manage the environment manually. Here you have several options, such as managing your own virtualenv, running in a Docker container, etc. Remove the
python_envtag fromfedn.yamlto handle the environment manually.
build (optional):
This entry point is used for any kind of setup that needs to be done to initialize FEDn prior to federated training. This is the only entrypoint not used by the client during global training rounds - rather it is used by the project initator. Most often it is used to build the seed model.
In the ‘mnist-pytorch’ example, build executes ‘model.py’ (shown below). This script contains the definition of the CNN model along with a main method
that instantiates a model object (with random weights), exctracts its parameters into a list of numpy arrays and writes them to a file “seed.npz”.
import collections
import torch
from fedn.utils.helpers.helpers import get_helper
HELPER_MODULE = "numpyhelper"
helper = get_helper(HELPER_MODULE)
def compile_model():
"""Compile the pytorch model.
:return: The compiled model.
:rtype: torch.nn.Module
"""
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = torch.nn.Linear(784, 64)
self.fc2 = torch.nn.Linear(64, 32)
self.fc3 = torch.nn.Linear(32, 10)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x.reshape(x.size(0), 784)))
x = torch.nn.functional.dropout(x, p=0.5, training=self.training)
x = torch.nn.functional.relu(self.fc2(x))
x = torch.nn.functional.log_softmax(self.fc3(x), dim=1)
return x
return Net()
def save_parameters(model, out_path):
"""Save model paramters to file.
:param model: The model to serialize.
:type model: torch.nn.Module
:param out_path: The path to save to.
:type out_path: str
"""
parameters_np = [val.cpu().numpy() for _, val in model.state_dict().items()]
helper.save(parameters_np, out_path)
def load_parameters(model_path):
"""Load model parameters from file and populate model.
param model_path: The path to load from.
:type model_path: str
:return: The loaded model.
:rtype: torch.nn.Module
"""
model = compile_model()
parameters_np = helper.load(model_path)
params_dict = zip(model.state_dict().keys(), parameters_np)
state_dict = collections.OrderedDict({key: torch.tensor(x) for key, x in params_dict})
model.load_state_dict(state_dict, strict=True)
return model
def init_seed(out_path="seed.npz"):
"""Initialize seed model and save it to file.
:param out_path: The path to save the seed model to.
:type out_path: str
"""
# Init and save
model = compile_model()
save_parameters(model, out_path)
if __name__ == "__main__":
init_seed("../seed.npz")
startup (optional):
The entry point ‘startup’ is used by the client. It is called once, immediately after the client starts up and the environment has been initalized. It can be used to do runtime configurations of the client’s local execution environment.
In the ‘mnist-pytorch’ project, the startup entry point invokes a script that downloads the MNIST dataset from an external server and creates a partition to be used by that client. Not all projects will specify a startup script. In the case of the mnist-pytorch example it is simply used as a convenience to automate experiments by splitting a publicly available dataset. However, in real-world settings with truly private data, the client will have the data locally.
train (mandatory):
This entry point is invoked when the client recieves a new model update (training) request from the server. The training entry point must be a single-input single-output (SISO) program. Upon recipt of a traing request, the FEDn client will download the latest version of the global model, write it to a (temporary) file and execute the command specified in the entrypoint:
python train.py model_in model_out
where ‘model_in’ is the file containing the current global model (parameters) to be updated, and ‘model_out’ is a path to write the new model update to (FEDn substitutes this path for tempfile location). When a traing update is complete, FEDn reads the updated paramters from ‘model_out’ and streams them back to the server for aggregation.
Note
The training entrypoint must also write metadata to a json-file. The entry num_example is mandatory - it is used by the aggregators to compute a weighted average. The user can in addition choose to log other variables such as hyperparamters. These will then be stored in the backend database and accessible via the API and UI.
In our ‘mnist-pytorch’ example, upon startup a client downloads the MNIST image dataset and creates partitions (one for each client). This partition is in turn divided into a train/test split. The file ‘train.py’ (shown below) reads the train split, runs an epoch of training and writes the updated paramters to file.
To learn more about how model serialization and model marshalling works in FEDn, see Model marshalling and Aggregators.
import math
import os
import sys
import torch
from model import load_parameters, save_parameters
from data import load_data
from fedn.utils.helpers.helpers import save_metadata
dir_path = os.path.dirname(os.path.realpath(__file__))
sys.path.append(os.path.abspath(dir_path))
def train(in_model_path, out_model_path, data_path=None, batch_size=32, epochs=1, lr=0.01):
"""Complete a model update.
Load model paramters from in_model_path (managed by the FEDn client),
perform a model update, and write updated paramters
to out_model_path (picked up by the FEDn client).
:param in_model_path: The path to the input model.
:type in_model_path: str
:param out_model_path: The path to save the output model to.
:type out_model_path: str
:param data_path: The path to the data file.
:type data_path: str
:param batch_size: The batch size to use.
:type batch_size: int
:param epochs: The number of epochs to train.
:type epochs: int
:param lr: The learning rate to use.
:type lr: float
"""
# Load data
x_train, y_train = load_data(data_path)
# Load parmeters and initialize model
model = load_parameters(in_model_path)
# Train
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
n_batches = int(math.ceil(len(x_train) / batch_size))
criterion = torch.nn.NLLLoss()
for e in range(epochs): # epoch loop
for b in range(n_batches): # batch loop
# Retrieve current batch
batch_x = x_train[b * batch_size : (b + 1) * batch_size]
batch_y = y_train[b * batch_size : (b + 1) * batch_size]
# Train on batch
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
# Log
if b % 100 == 0:
print(f"Epoch {e}/{epochs-1} | Batch: {b}/{n_batches-1} | Loss: {loss.item()}")
# Metadata needed for aggregation server side
metadata = {
# num_examples are mandatory
"num_examples": len(x_train),
"batch_size": batch_size,
"epochs": epochs,
"lr": lr,
}
# Save JSON metadata file (mandatory)
save_metadata(metadata, out_model_path)
# Save model update (mandatory)
save_parameters(model, out_model_path)
if __name__ == "__main__":
train(sys.argv[1], sys.argv[2])
validate (optional):
When training a global model with FEDn, the data scientist can choose to ask clients to perform local model validation of each new global model version by specifying an entry point called ‘validate’.
Similar to the training entrypoint, the validation entry point must be a SISO program. It should reads a model update from file, validate it (in any way suitable to the user), and write a json file containing validation data:
python validate.py model_in validations.json
The content of the file ‘validations.json’ is captured by FEDn, passed on to the server and then stored in the database backend. The validate entry point is optional.
In our ‘mnist-pytorch’ example, upon startup a client downloads the MNIST image dataset and creates partitions (one for each client). This partition is in turn divided into a train/test split. The file ‘validate.py’ (shown below) reads both the train and test splits and computes accuracy scores and the loss.
It is a requirement that the output of validate.py is valid json. Furthermore, the FEDn Studio UI will be able to capture and visualize all scalar metrics specified in this file. The entire conent of the json file will be retrievable programatically using the FEDn APIClient, and can be downloaded from the Studio UI.
import os
import sys
import torch
from model import load_parameters
from data import load_data
from fedn.utils.helpers.helpers import save_metrics
dir_path = os.path.dirname(os.path.realpath(__file__))
sys.path.append(os.path.abspath(dir_path))
def validate(in_model_path, out_json_path, data_path=None):
"""Validate model.
:param in_model_path: The path to the input model.
:type in_model_path: str
:param out_json_path: The path to save the output JSON to.
:type out_json_path: str
:param data_path: The path to the data file.
:type data_path: str
"""
# Load data
x_train, y_train = load_data(data_path)
x_test, y_test = load_data(data_path, is_train=False)
# Load model
model = load_parameters(in_model_path)
model.eval()
# Evaluate
criterion = torch.nn.NLLLoss()
with torch.no_grad():
train_out = model(x_train)
training_loss = criterion(train_out, y_train)
training_accuracy = torch.sum(torch.argmax(train_out, dim=1) == y_train) / len(train_out)
test_out = model(x_test)
test_loss = criterion(test_out, y_test)
test_accuracy = torch.sum(torch.argmax(test_out, dim=1) == y_test) / len(test_out)
# JSON schema
report = {
"training_loss": training_loss.item(),
"training_accuracy": training_accuracy.item(),
"test_loss": test_loss.item(),
"test_accuracy": test_accuracy.item(),
}
# Save JSON
save_metrics(report, out_json_path)
if __name__ == "__main__":
validate(sys.argv[1], sys.argv[2])
Testing the entrypoints
We recommend you to test your training and validation entry points locally before creating the compute package and uploading it to Studio. To run the ‘build’ entrypoint and create the seed model (deafult filename ‘seed.npz’):
fedn run build --path client
Run the ‘startup’ entrypoint to download the dataset:
fedn run startup --path client
Then, standing inside the ‘client folder’, you can test train and validate by:
python train.py ../seed.npz ../model_update.npz --data_path data/clients/1/mnist.pt
python validate.py ../model_update.npz ../validation.json --data_path data/clients/1/mnist.pt
You can also test train and validate entrypoint using CLI command:
Note
Before running the fedn run train or fedn run validate commands, make sure to download the training and test data. The downloads are usually handled by the “fedn run startup” command in the examples provided by FEDn.
fedn run train --path client --input <path to input model parameters> --output <path to write the updated model parameters>
fedn run validate --path client --input <path to input model parameters> --output <path to write the output JSON containing validation metrics>
Packaging for training on FEDn
To run a project on FEDn we compress the entire client folder as a .tgz file. There is a utility command in the FEDn CLI to do this:
fedn package create --path client
You can include a .ignore file in the client folder to exclude files from the package. This is useful for excluding large data files, temporary files, etc. To learn how to initialize FEDn with the package seed model, see Getting started with FEDn.
How is FEDn using the project?
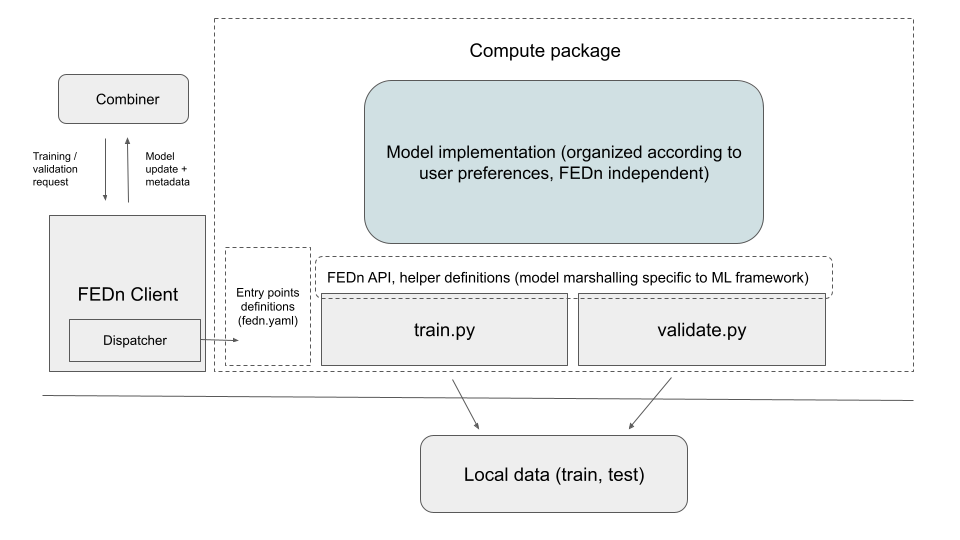
With an understanding of the FEDn project, the compute package (entrypoints), we can take a closer look at how FEDn is using the project during federated training. The figure below shows the logical view of how a training request is handled.
A training round is initiated by the controller. It asks a Combiner for a model update. The model in turn asks clients to compute a model update, by publishing a training request
to its request stream. The FEDn Client, fedn.network.client, subscribes to the stream and picks up the request. It then calls upon the Dispatcher, fedn.utils.Dispatcher.
The dispatcher reads the Project File, ‘fedn.yaml’, looking up the entry point definition and executes that command. Upon successful execution, the FEDn Client reads the
model update and metadata from file, and streams the content back to the combiner for aggregration.
Where to go from here?
With an understanding of how FEDn Projects are structured and created, you can explore our library of example projects. They demonstrate different use case scenarios of FEDn and its integration with popular machine learning frameworks like PyTorch and TensorFlow.